pytorch分类和回归代码实现
本文共 6558 字,大约阅读时间需要 21 分钟。
#pytorch神经网络搭建主要就是如下步骤:
a、准备数据 b、搭建层架构(input,隐藏层,output) c、loss和optimizer优化 d、反向传播更新1.分类
import torchimport torch.nn.functional as Fimport matplotlib.pyplot as plt# torch.manual_seed(1) # reproducible# make fake datan_data = torch.ones(100, 2)x0 = torch.normal(2*n_data, 1) # class0 x data (tensor), shape=(100, 2)y0 = torch.zeros(100) # class0 y data (tensor), shape=(100, 1)x1 = torch.normal(-2*n_data, 1) # class1 x data (tensor), shape=(100, 2)y1 = torch.ones(100) # class1 y data (tensor), shape=(100, 1)x = torch.cat((x0, x1), 0).type(torch.FloatTensor) # shape (200, 2) FloatTensor = 32-bit floatingy = torch.cat((y0, y1), ).type(torch.LongTensor) # shape (200,) LongTensor = 64-bit integer# The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors# x, y = Variable(x), Variable(y)# plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=y.data.numpy(), s=100, lw=0, cmap='RdYlGn')# plt.show()class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer self.out = torch.nn.Linear(n_hidden, n_output) # output layer def forward(self, x): x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.out(x) return xnet = Net(n_feature=2, n_hidden=10, n_output=2) # define the networkprint(net) # net architectureoptimizer = torch.optim.SGD(net.parameters(), lr=0.02)loss_func = torch.nn.CrossEntropyLoss() # the target label is NOT an one-hottedplt.ion() # something about plottingfor t in range(100): out = net(x) # input x and predict based on x loss = loss_func(out, y) # must be (1. nn output, 2. target), the target label is NOT one-hotted optimizer.zero_grad() # clear gradients for next train loss.backward() # backpropagation, compute gradients optimizer.step() # apply gradients if t % 2 == 0: # plot and show learning process plt.cla() prediction = torch.max(out, 1)[1] pred_y = prediction.data.numpy() target_y = y.data.numpy() plt.scatter(x.data.numpy()[:, 0], x.data.numpy()[:, 1], c=pred_y, s=100, lw=0, cmap='RdYlGn') accuracy = float((pred_y == target_y).astype(int).sum()) / float(target_y.size) plt.text(1.5, -4, 'Accuracy=%.2f' % accuracy, fontdict={'size': 20, 'color': 'red'}) plt.pause(0.1)plt.ioff()plt.show() 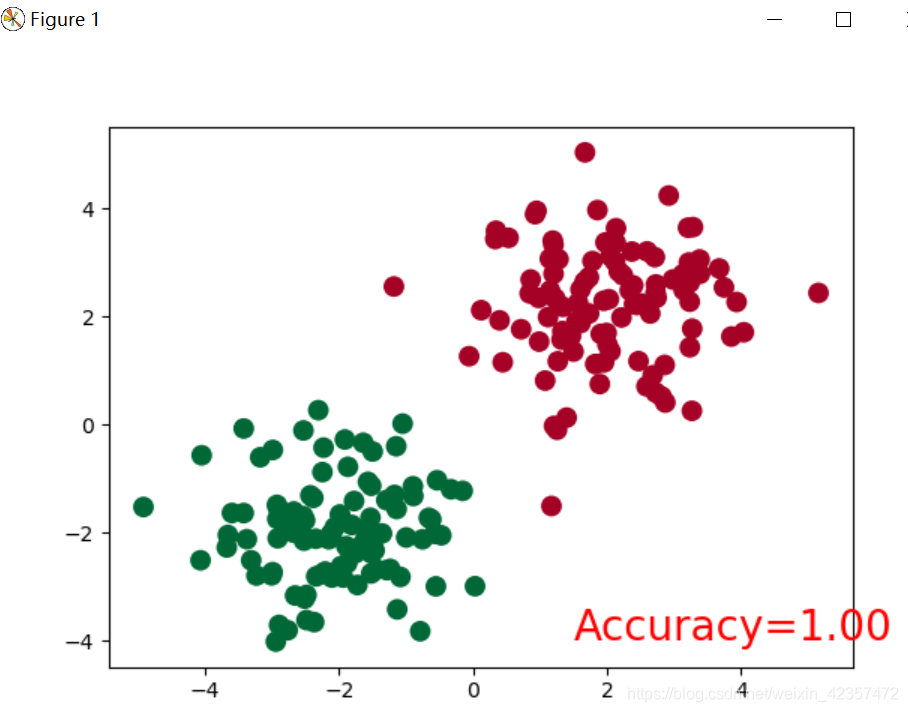
2,回归
import torchimport torch.nn.functional as Fimport matplotlib.pyplot as plt# torch.manual_seed(1) # reproduciblex = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)y = x.pow(2) + 0.2*torch.rand(x.size()) # noisy y data (tensor), shape=(100, 1)# torch can only train on Variable, so convert them to Variable# The code below is deprecated in Pytorch 0.4. Now, autograd directly supports tensors# x, y = Variable(x), Variable(y)plt.scatter(x.data.numpy(), y.data.numpy())plt.show()#第一种模型搭建方式class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() self.hidden = torch.nn.Linear(n_feature, n_hidden) # hidden layer self.predict = torch.nn.Linear(n_hidden, n_output) # output layer def forward(self, x): x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.predict(x) # linear output return x#第二种模型搭建方式class Net(torch.nn.Module): def __init__(self, n_feature, n_hidden, n_output): super(Net, self).__init__() self.mode1 = torch.nn.Sequential( torch.nn.Linear(n_feature, n_hidden), torch.nn.ReLU(), torch.nn.Linear(n_hidden, n_output) ) def forward(self, x): # x = F.relu(self.hidden(x)) # activation function for hidden layer x = self.mode1(x) # linear output return xnet = Net(n_feature=1, n_hidden=10, n_output=1) # define the networkprint(net) # net architectureoptimizer = torch.optim.SGD(net.parameters(), lr=0.2)loss_func = torch.nn.MSELoss() # this is for regression mean squared lossplt.ion() # something about plottingfor t in range(200): prediction = net(x) # input x and predict based on x loss = loss_func(prediction, y) # must be (1. nn output, 2. target) optimizer.zero_grad() # clear gradients for next train loss.backward() # backpropagation, compute gradients optimizer.step() # apply gradients if t % 5 == 0: # plot and show learning process plt.cla() plt.scatter(x.data.numpy(), y.data.numpy()) plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5) plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'}) plt.pause(0.1)plt.ioff()plt.show() 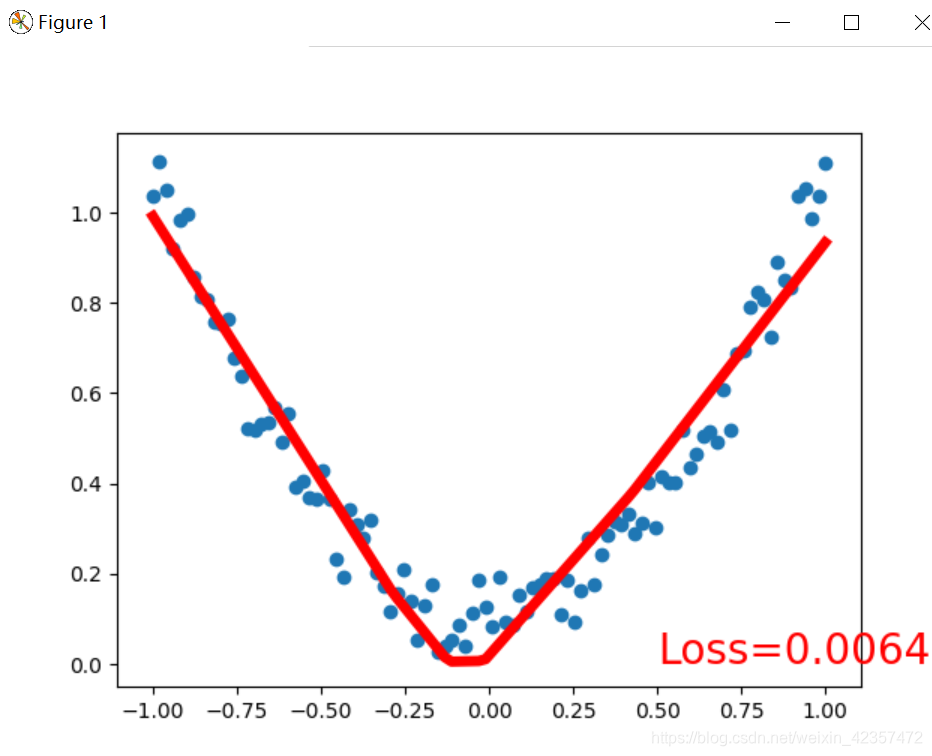
import torchfrom torch import nn, optimfrom torch.autograd import Variableimport numpy as npimport matplotlib.pyplot as pltx_train = np.array([[3.3], [4.4], [5.5], [6.71], [6.93], [4.168], [9.779], [6.182], [7.59], [2.167], [7.042], [10.791], [5.313], [7.997], [3.1]], dtype=np.float32)y_train = np.array([[1.7], [2.76], [2.09], [3.19], [1.694], [1.573], [3.366], [2.596], [2.53], [1.221], [2.827], [3.465], [1.65], [2.904], [1.3]], dtype=np.float32)x_train = torch.from_numpy(x_train)y_train = torch.from_numpy(y_train)# Linear Regression Modelclass LinearRegression(nn.Module): def __init__(self): super(LinearRegression, self).__init__() self.linear = nn.Linear(1, 1) # input and output is 1 dimension def forward(self, x): out = self.linear(x) return outmodel = LinearRegression()# 定义loss和优化函数criterion = nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=1e-4)# 开始训练num_epochs = 1000for epoch in range(num_epochs): inputs = Variable(x_train) target = Variable(y_train) # forward out = model(inputs) loss = criterion(out, target) # backward optimizer.zero_grad() loss.backward() optimizer.step() if (epoch+1) % 20 == 0: print('Epoch[{}/{}], loss: {:.6f}'.format(epoch+1, num_epochs, loss.item())) # .format(epoch+1, num_epochs, loss.data[0]))model.eval()predict = model(Variable(x_train))predict = predict.data.numpy()plt.plot(x_train.numpy(), y_train.numpy(), 'ro', label='Original data')plt.plot(x_train.numpy(), predict, label='Fitting Line')# 显示图例plt.legend()plt.show() 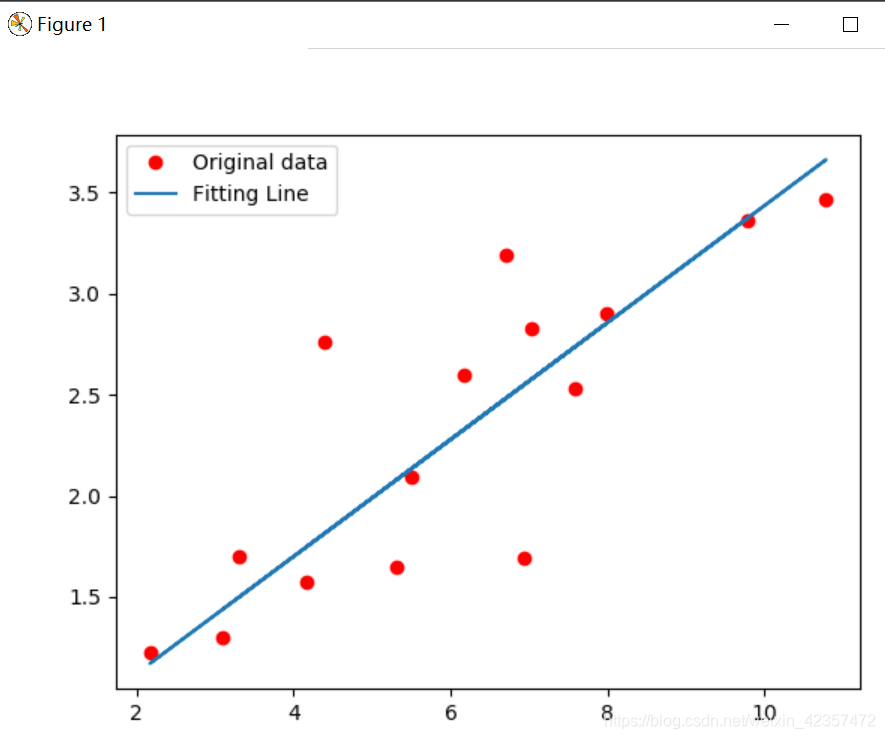
转载地址:http://jfxp.baihongyu.com/
你可能感兴趣的文章
Mysql InnoDB存储引擎中的checkpoint技术
查看>>
Mysql InnoDB存储引擎中缓冲池Buffer Pool、Redo Log、Bin Log、Undo Log、Channge Buffer
查看>>
MySQL InnoDB引擎的锁机制详解
查看>>
Mysql INNODB引擎行锁的3种算法 Record Lock Next-Key Lock Grap Lock
查看>>
mysql InnoDB数据存储引擎 的B+树索引原理
查看>>
mysql innodb通过使用mvcc来实现可重复读
查看>>
mysql insert update 同时执行_MySQL进阶三板斧(三)看清“触发器 (Trigger)”的真实面目...
查看>>
mysql interval显示条件值_MySQL INTERVAL关键字可以使用哪些不同的单位值?
查看>>
Mysql join原理
查看>>
MySQL Join算法与调优白皮书(二)
查看>>
Mysql order by与limit混用陷阱
查看>>
Mysql order by与limit混用陷阱
查看>>
mysql order by多个字段排序
查看>>
MySQL Order By实现原理分析和Filesort优化
查看>>
mysql problems
查看>>
mysql replace first,MySQL中处理各种重复的一些方法
查看>>
MySQL replace函数替换字符串语句的用法(mysql字符串替换)
查看>>
mysql replace用法
查看>>
Mysql Row_Format 参数讲解
查看>>
mysql select, from ,join ,on ,where groupby,having ,order by limit的执行顺序和书写顺序
查看>>